August 18, 2018
Die menschliche Intelligenz simulieren: AI - So schlau wie ein Mensch?
Bei der Künstlichen Intelligenz (AI) geht es um die Bildung von Modellen der realen Welt, die in Computeralgorithmen dargestellt werden. Diese Modelle ermöglichen es, intelligentes Verhalten zu nachzubilden, das dem menschlichen Verhalten oder menschlicher Intelligenz ähnelt. Wie eingangs erwähnt, gibt es unterschiedliche Auffassungen vom Begriff AI. Mit AI ist in der modernen Literatur Folgendes gemeint:
Intelligenzniveau der Maschinen: starke (allgemeine) AI/KI und schwache (schmale) AI/KI
Wenn wir von AI/KI sprechen, unterscheiden wir zwischen starker und schwacher AI/KI. AI/KI hat etwas mit Denken, Wahrnehmen und Handeln zu tun. Wir versuchen, die menschliche Intelligenz zu simulieren. Starke AI/KI oder allgemeine AI/KI hat die volle Fähigkeit des menschlichen Verstehens. Bis heute gibt es kein Beispiel für eine starke AI/KI (außerhalb von Filmen). Wie Erik Cambria, ein Experte auf dem Gebiet der natürlichen Sprachverarbeitung, sagt: “Es gibt heute nichts, was so intelligent ist wie der dümmste Mensch der Welt. Also, im engeren Sinne, macht noch niemand AI/KI, aus der einfachen Tatsache heraus, dass wir nicht wissen, wie das menschliche Gehirn funktioniert” (Singularityhub, 2018).
Schwache AI/KI ist ein realistisches Konstrukt, das Programme und Computer in die Lage versetzt, bestimmte Aufgaben zumindest so gut auszuführen, wie ein Mensch sie ausführen könnte. Schwache AI/KI ist das, was wir in den heutigen AI/KI-Anwendungen sehen.
Maschinelles Lernen und Deep Learning
Machine Learning und Deep Learning sind Teilmengen von AI/KI. Man kann sich Deep Learning, maschinelles Lernen und künstliche Intelligenz als einen Satz russischer Puppen vorstellen, die ineinander verschachtelt sind: Deep Learning ist ein Teil des maschinellen Lernens und maschinelles Lernen ist ein Teil der AI/KI.
Maschinelles Lernen als Teil der AI/KI: ein Algorithmus, der aus Daten lernen kann.
Das maschinelle Lernen nutzt Modelle zur Vorhersage. Es ist ein Algorithmus, der aus Daten lernen kann. Man kann ein maschinelles Lernmodell mit Daten versorgen und es wird Vorhersagen über die Zukunft machen. 1959 definierte Arthur Samuel maschinelles Lernen als “Studienfach, das Computern die Fähigkeit gibt zu lernen, ohne explizit programmiert zu sein”. Maschinen lernen, Aufgaben auszuführen, für die sie nicht speziell programmiert sind. Die generelle Vorgehensweise beim maschinellen Lernen sieht typischerweise wie folgt aus: - Identifizierung eines Anwendungsfalles (Business Problem, Use Case) - Entwickeln einer Hypothese basierend auf diesem Problem - Sammeln von Daten aus verschiedenen Quellen (Aufbau der Datenpipeline) - Bereinigung der Daten - Modellbildung: Auswahl des richtigen ML-Algorithmus - Das Modell mit Hilfe der Daten trainieren - Erkenntnisse aus den Modellergebnissen gewinnen - Datenvisualisierung: Visualisierung der Datenergebnisse (analyticsvidhya, 2016)
Ein einfaches Beispiel ist die lineare Regression, die eine beobachtete abhängige Variable durch eine oder mehrere unabhängige Variablen erklärt. Man könnte die lineare Regression verwenden, um die Ringgröße über die Körpergröße einer Person schätzen. Zu den Methoden, die von maschinellen Lernanwendungen verwendet werden, gehören supervised learning, reinforcement learning und unsupervised learning.
Supervised learning: Abbildung der Funktion zwischen Eingangs- und Ausgangssignalen
Beim supervised learning benötigt man gelabelte Daten, was bedeutet, dass die Ausgangssignale bekannt sind. Es existieren also sowohl Input- als auch Outputdaten. Das Ziel ist es nun, Vorhersagen über zukünftige Daten zu treffen, dass heißt den Zusammenhang zwischen Input und Output zu modellieren. Verwendet wird dazu ein Algorithmus, um die Funktion, die den Übergang von Eingangs- zu Ausgangssignalen beschreibt, zu lernen - die sogenannte Mapping-Funktion.
Beispiel: Angenommen, man hat Daten von den Abonnenten einer Zeitschrift. Einige der Nutzer haben bereits gekündigt, andere noch nicht. Nun können die bestehenden Daten untersucht werden, um eine Vorhersage darüber zu treffen, wie schnell oder unter welchen Bedingungen ein Abonnent kündigen wird.
Unsupervised learning
Beim unsupervised learning geht es um das allgemeine Verstehen der vorliegenden Daten. Man wendet unsupervised learning an, wenn man noch nicht weiß, was die Zusammenhänge in den Daten sein könnten. Meistens sind die große Datenmengen zu komplex, um eine Beziehung von vornherein zu erkennen. Man nennt das Ganze auch “Knowledge Discovery”, was nichts anderes als das Entdecken von versteckten Strukturen in Daten.
Beispiel: Man hat bestimmte Nutzerdaten und Filme auf Netflix und möchte wissen, welche Zusammenhänge zwischen der Auswahl eines Filmes und den demografischen Eigenschaften der Nutzer bestehen, um bessere Vorschläge für weitere Filme und Genres machen zu können.
Reinforcement learning: Lernen durch Interaktion mit der Umwelt
Bei manchen Problemen kann die Erstellung einer Datenbasis um das Modell zu trainieren eine zu komplexe Aufgabe sein. Zum Beispiel beim Training eines Modells für das Schachspiel. In diesem Fall könnten reinforcement learning angewandt werden. Beim reinforcement learning wird ein Algorithmus verwendet, der aus den Konsequenzen des Handelns lernt und nicht aus explizitem Training mit einer vorhandenen Datenbasis. Sowohl beim supervised learning als auch beim reinforcement learning gibt es ein Mapping zwischen Input und Output. Beim reinforcement learning gibt es eine Belohnungsfunktion, die im Gegensatz zum supervised learning als Feedback an den Agenten fungiert. Ziel ist es, ein System zu entwickeln, das seine Ergebnisse durch Interaktionen mit der Umwelt verbessert. Es ist vergleichbar mit dem Konzept des Learning by doing und wird für Probleme verwendet, mit denen Menschen im Alltag konfrontiert sind. Reinforcement learning soll die Hoffnung auf eine echte AI/KI sein.
Deep Learning als Teil von Machine Learning
Eine der größten Herausforderungen für künstliche Intelligenz ist es, informelles Wissen abzubilden. Aufgaben, die für den Menschen intuitiv leicht zu erfüllen sind, jedoch für Maschinen schwer zu bewältigen sind, sind Inhalte für Deep Learning (wie bspw. Gesichtserkennung und Spracherkennung). Solche Dinge sind durch mathematische Algorithmen schwer zu modellieren. Computer müssen das Wissen jedoch erfassen können, um sich intelligent zu verhalten. Die meisten Deep-Learning-Algorithmen nutzen Architekturen in Form von neuronalen Netzen und lernen aus Daten in einer inkrementellen Art und Weise. Sie nehmen die Welt als ein Konzept mehrerer hierarchisch strukturierter Schichten wahr, in dem jede Ebene die Informationen der vorherigen Ebene weiter verwendet um zu lernen und die Ausgabe ihrerseits an die nächste Schicht weiter leitet. Das Ergebnis wird in der sichtbaren “Ausgabeschicht”, der letzten Schicht, ausgegeben. Der Begriff „deep“ bzw. tief bezieht sich im Allgemeinen auf die Anzahl verborgener Schichten des neuronalen Netzes. Durch dieses Schichtenmodell sind sie in der Lage, komplexe Konzepte und Muster zu modellieren. Es erscheint zwar kontraintuitiv, aber die Ausgabe eines Deep-Learning-Modell ist nicht interpretierbar, dass heißt, dass es nicht nachvollziehbar ist, wie das Netz zu seinem Ergebnis gekommen ist. Deep Learning erfordert eine große Menge an klassifizierten Daten und sehr viel Rechenleistung, um die Daten zu verarbeiten. Die einzelnen Vorgänge, wie die Ebenen gelernt und Entscheidungen auf Basis der Daten getroffen haben, sind letztlich nicht ersichtlich. Bei der Wahl zwischen anderen Machine Learning Methoden und Deep Learning sollte man berücksichtigen, ob man Zugang zu Hochleistungs-GPU (Graphic Processing Unit) sowie umfangreichen klassifizierten Datensätzen (Datensätze sind klassifiziert, wenn z.B. für alle Bilder die Angabe Katze oder nicht Katze angegeben ist) hat. Soll der Weg zwischen Eingabe und Ausgabe des Modells nachvollziehbar sein, spricht dies ebenfalls gegen Deep Learning. Beispiel: Man könnte ein neutrales Netz dazu nutzen, Katzen automatisch auf Bildern erkennen zu lassen. Um das notwendige Wissen zu erlangen wie eine Katze aussieht, muss das Netzwerk zunächst mit Daten trainiert werden. Wir brauchen also einen klassifizierten Datensatz, der Katzen zeigt. Die Eingabe-Schicht unseres neuronalen Netzes braucht für dieses Beispiel genug Neuronen um jeden Pixel des Bildes aufzunehmen, welches wir nutzen wollen. Wir ergänzen eine Output-Schicht mit zwei Neuronen von denen eines „Katze“ signalisiert und eines „keine Katze“. Nun fügt man ein paar weitere Schichten von Neuronen hinzu und verbindet diese miteinander. Ihre hierarchische Anordnung führt dazu, dass bspw. die erste Schicht grobe Kanten und Formen erkennt, während weitere Schichten daraufhin genauere Strukturen Merkmale und Abhängigkeiten erkennen können (siehe Bild unten für ein menschliches Beispiel. Quelle: towardsdatascience).
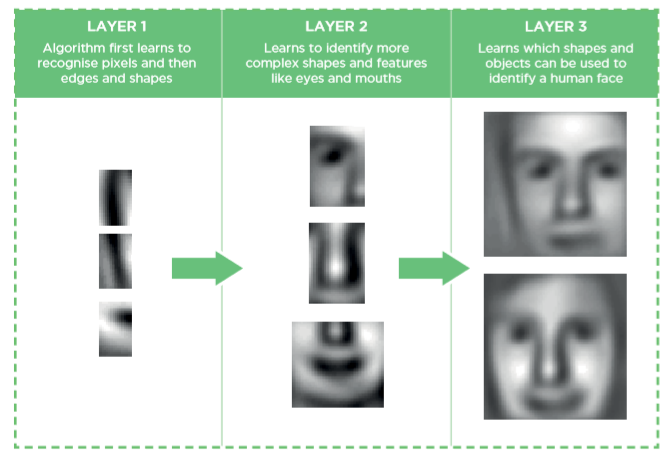
Große Datenmengen, gute Modelle sowie ausreichend Rechenpower machen Artificial Intelligence also möglich. Aber was genau ist Artificial Intelligence eigentlich und wo sind ihre Grenzen? Zum nächsten Teil unserer Serie geht es hier: lest hier den nächsten Teil zu Artificial Intelligence. Solltet ihr den ersten Teil noch nicht gelesen haben, dann schaut hier
Unser Nächstes Meetup zu dem Thema wird am 19. September in München bei Google stattfinden. Tretet am besten jetzt schon einmal unserer Meetup Gruppe bei.
Wenn ihr Euch näher mit Machine Learning beschäftigen möchtet ist ein Python Kurs ein guter Start. Hier findet ihr mehr Infos zu den aktuellen Terminen.
Anja Schumann